 Why your AI roadmap is doomed without a parallel data product strategy, and how to build the “AI-Data Contract” to ensure they succeed together. Image generated with gpt4o
Why your AI roadmap is doomed without a parallel data product strategy, and how to build the “AI-Data Contract” to ensure they succeed together. Image generated with gpt4o
The warnings aren’t subtle: Gartner predicted in 2024 that a staggering 30% of generative AI projects would be abandoned by 2025, or that a 40% of agentic AI projects would be canceled by 2027. The same source also indicates only a 48% of AI projects ended up in production in 2024. In the same vein NTT asserted that 70–85% of GenAI initiatives fail to meet expected ROI, citing human-based factors like change fatigue and lack of trust alongside data issues.
These problematic scenarios weren’t primarily due to technical questions or budget allocation matters, but rather than to bias in the data or the teams managing it. Poor data quality put an average tax of $12.9 million per year on organizations.
The post-mortems for these failed projects often sound the same: the model drifted, the predictions were biased, the ROI never materialized. But these are symptoms, not the disease. The root cause is a fundamental strategic error: treating the data that fuels AI as an operational byproduct—an exhaust fume from source systems—rather than as the refined fuel it must be. AI and data strategies are too often managed in separate silos, with separate roadmaps, separate teams, and separate metrics for success. This fractured approach is a blueprint for failure.
The only viable path forward is to treat Data and AI as a Twin Engine, two tightly coupled, co-dependent systems that power the enterprise forward. One cannot function optimally without the other. This article lays out the framework for this essential integration. We will map every stage of the AI lifecycle to its corresponding Data as a Product counterpart. We will introduce the AI-Data Contract, an operational pact that binds these two engines together. Finally, we will provide a strategic checklist for leaders to make this framework a reality. Your AI ambitions are only as strong as the data products they are built upon. It’s time to build them together.
1. The Twin Engine Framework: Mapping Your AI and Data Roadmaps
For every ambitious step in your AI roadmap, there must be a corresponding, deliberate step in your data product strategy. Without this parallel execution, your AI initiatives are running on one engine, destined to stall. The Twin Engine framework synchronizes these efforts, ensuring that data is not just an input, but a managed, reliable product designed explicitly for AI consumption.
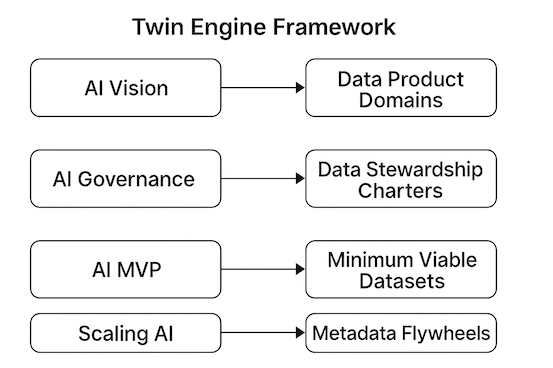 Figure 1: Diagram of the Twin Engine Framework, showing AI Vision mapping to Data Product Domains, AI Governance to Data Stewardship Charters, AI MVP to Minimum Viable Datasets, and Scaling AI to Metadata Flywheels.
Figure 1: Diagram of the Twin Engine Framework, showing AI Vision mapping to Data Product Domains, AI Governance to Data Stewardship Charters, AI MVP to Minimum Viable Datasets, and Scaling AI to Metadata Flywheels.
What's a Data Product?
Imagine a data product like a packaged, ready-to-use set of data designed for others to easily find, understand, and use. Instead of dumping raw data into a big central system, each team creates and owns these data products — they clean, organize, and document the data so it’s trustworthy and can be reused by others across the company, like marketing or finance, without extra work. Think of it like a well-labeled, high-quality ingredient in a kitchen that anyone can grab and cook with.
1.1: AI Vision ↔️ Data Product Domains
An AI vision that aims to “revolutionize customer experience” or “optimize global supply chains” is an empty promise without a data strategy to match. Grand visions require thinking about data not as a monolithic lake or warehouse, but as a portfolio of business-aligned Domains. As Thoughtworks define it, Data as a Product means treating datasets as standalone, managed products with clear owners, defined interfaces, and consumers they are meant to serve.
Your AI vision to create a hyper-personalized recommendation engine is inert until the “Customer” data domain team delivers a trusted, 360-degree view of the customer as a product. The goal to build a fraud detection system depends entirely on the “Transactions” domain providing a clean, real-time, and well-documented data product. By organizing data capabilities around business domains—like Customer, Product, or Logistics—you align data ownership with business outcomes. The domain team’s success is measured by the quality and utility of the data products they provide to consumers, including AI teams. Without this domain-oriented structure, AI teams are left to forage for data across a chaotic landscape, a process that kills momentum and dooms ambitious visions from the start.
What's a Data Domain?
A data business domain (or just a Data Domain) is an abstraction representing a specific area of the company where people, processes, and data revolve around the same purpose. It’s a way to group everything related to one part of the business — like “Sales,” “Logistics,” or “Customer Support” — so data can be organized and modeled around how that area actually works. Think of it as a “territory” with its own language and rules that helps make sense of the data in that context.
1.2: AI Governance ↔️ Data Stewardship Charters
AI Governance is often mistaken for a high-level ethics committee that meets quarterly. In reality, effective governance is an operational discipline. It cannot be enforced by slide decks; it must be embedded in the teams that handle the data. This is where AI Governance finds its twin: Data Stewardship Charters.
A Stewardship Charter is a mandate for the data domain team. It’s a document that codifies their responsibilities for the data products they own. As the data catalog company Atlan emphasizes, establishing organizational data stewardship is about assigning clear accountability. The charter for the “Customer” domain team wouldn’t just task them with managing customer data; it would explicitly hold them accountable for its accuracy, its freedom from bias, its compliance with privacy regulations like GDPR, and the clarity of its documentation. When an AI model is audited for fairness, it’s the Stewardship Charter that provides the chain of custody and accountability. AI governance committees can set the rules, but Stewardship Charters ensure those rules are operationalized by the people closest to the data itself.
About Governance?
Governance is the set of rules, roles, and processes that ensure an organization’s activities stay aligned with its goals, standards, and regulations.
- Data Governance is the framework that defines who can access, modify, and use each piece of data, how data quality is maintained, and which policies ensure data is secure, compliant, and trustworthy.
- AI Governance extends this idea to algorithms and models: it sets the guidelines for how AI systems are developed, tested, deployed, and monitored, covering ethics, fairness, transparency, and accountability so that AI-driven decisions stay reliable and aligned with legal and ethical standards.
1.3: AI MVP ↔️ Minimum Viable Datasets (MVD)
No team would attempt to build a software Minimum Viable Product (MVP) without a stable codebase and reliable APIs. Yet, teams routinely try to build AI MVPs on a foundation of ad-hoc data pulls and unverified spreadsheets. This approach is a recipe for models that work once in a notebook but fail spectacularly in production. The twin of the AI MVP is the Minimum Viable Dataset (MVD).
An MVD, as defined by sources like Forbes Advisor and Altoros, is not just a sample of data. It is the first version of a true data product: a trusted, documented dataset with explicit quality guarantees. It has a defined schema, known lineage, and published metrics for freshness and completeness. For example, an AI team building a churn prediction MVP doesn’t just need “some usage data.” They need an MVD from the “User Activity” domain that guarantees the data is updated within the last 24 hours, contains no PII in specified fields, and has a 99.5% completion rate for key features. Building the AI model on an MVD de-risks the entire project. It ensures that if the model underperforms, the problem is likely the logic, not undiscovered rot in the underlying data.
A Minimum Product Viable (MVP)
A Minimum Viable Product (MVP) is the simplest version of a product that delivers just enough features to solve a core problem, attract early users, and gather feedback for improvements. It lets you learn what works (and what doesn’t) without wasting time building extras. Think of it as a “first draft” you can test, tweak, and expand based on real user insights.
1.4: Scaling AI ↔️ Metadata Flywheels
The first AI model is a project. The hundredth is an industrial process. Scaling from one successful model to an enterprise-wide AI capability is impossible without a mechanism for discovery, trust, and reuse. The engine for scaling AI is the Metadata Flywheel.
Metadata is the context that turns raw data into a usable asset. It’s the schema, the lineage, the quality scores, the business glossary definitions, and the usage statistics. The Metadata Flywheel is a virtuous cycle: every new data product published and every new AI model deployed enriches a central discovery platform (a data catalog) with more metadata. When a new AI team wants to build a model, they don’t start by interviewing people. They start at the catalog, searching for certified data products. They can see who uses a dataset, how it’s rated, and whether its quality SLOs are being met. This flywheel accelerates development, prevents redundant work, and builds a culture of trust and reuse. Scaling AI isn’t about hiring more data scientists; it’s about making each one more effective by providing a searchable, trustworthy landscape of data products.
Flyweels
This metaphor likens the process of building and scaling AI to spinning a heavy wheel: each time you publish a data product or deploy a model, you add more metadata—quality scores, lineage, usage stats, glossary terms—into a central catalog, just like giving the wheel another push. As that catalog fills out, it becomes easier and faster for new teams to discover, trust, and reuse existing assets, which in turn fuels even more contributions of metadata. Over time, the flywheel gains momentum—development accelerates, duplication vanishes, and every AI effort becomes more efficient—turning a one-off project into a smooth, industrial-strength process.
2. The AI-Data Contract: The Pact That Binds
The friction is a classic organizational scar. Imagine a machine learning team deploys a new forecasting model. Its performance is measured by uptime and prediction accuracy, with bonuses tied to hitting those KPIs. Three months later, the model’s accuracy plummets. A frantic audit reveals the cause: an upstream data engineering team, measured on their ability to ingest data cheaply and quickly, “optimized” a source table, silently changing a key column’s format from a timestamp to an integer. The model broke, the business lost money, and the teams blamed each other.
This isn’t a people problem; it’s a systems problem. The model owners had performance goals, but the data providers did not have corresponding, binding obligations to them. The solution is the AI-Data Contract: a formal, operational pact between a data product team and an AI model team. It’s not a document stored in a wiki; it is a live agreement, enforced by code and monitored continuously.
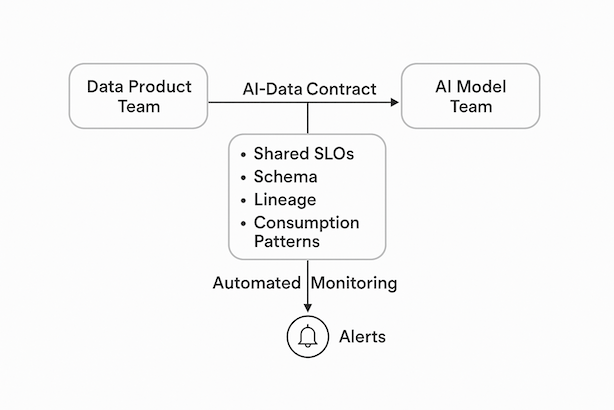 Firgure 2: Visualization of the AI-Data Contract flow, showing the data product team and the AI model team agreeing on shared SLOs, schema, lineage, and consumption patterns, with automated monitoring and alerts.
Firgure 2: Visualization of the AI-Data Contract flow, showing the data product team and the AI model team agreeing on shared SLOs, schema, lineage, and consumption patterns, with automated monitoring and alerts.
The AI-Data Contract is built on four pillars:
- Shared SLOs (Service Level Objectives): The contract moves beyond vague promises. It contains explicit, measurable targets for the data product that are directly tied to the health of the AI model. For instance:
- Freshness: The
customer_transactionsdata product will be updated within 5 minutes of a transaction clearing. - Completeness: The
user_profiledata product will have a 99.8% completion rate for thecountry_codefield. - Accuracy: The
product_catalogdata product guarantees a 99.99% match rate against the master inventory system.
These aren’t just data quality metrics; they are production dependencies for the AI model, as critical as server uptime. As Datadog and Blameless note in the SRE world, SLOs are the key to reliability.
-
Schema as Code: The contract treats the data’s structure as a critical piece of infrastructure. The schema—field names, data types, and constraints—is defined in a machine-readable format like JSON Schema or Avro and checked into a version-controlled repository like Git. Any proposed change to the schema must go through a pull request. This change automatically triggers a notification to the consuming AI team. Critical changes can be programmatically blocked until the AI team signs off, preventing the silent, breaking changes that kill models in production.
-
Lineage Guarantees: The data product team contractually guarantees that the data will have transparent, machine-readable lineage. The AI team must be able to programmatically query the origin of every field they consume. If a model is audited for bias, the team can instantly trace a problematic feature back to its source system, transformations, and owners. This isn’t just for debugging; it’s a fundamental requirement for risk management and regulatory compliance.
-
Consumption Patterns: The pact is a two-way street. The AI team agrees to consume the data product only through approved, versioned APIs or access points. They agree not to scrape internal databases or read from unofficial staging tables. This ensures that the data product team can evolve the asset without breaking unknown downstream dependencies. It creates stability for the producer and predictability for the consumer.
The AI-Data Contract transforms the relationship between data and AI teams from one of friction and finger-pointing to one of shared accountability, enforced by the platform itself.
3. Making It Real: Your Strategic Checklist
The Twin Engine framework and the AI-Data Contract are not academic exercises. They are strategic imperatives that require deliberate action and investment. For CDOs, CIOs, and platform architects, the task is to translate this vision into an executable plan. Here is your checklist.
Checklist Item 1: Stand Up Your First Data Mesh Squad.
Your first move is organizational. A data mesh, as evangelized by Thoughtworks, is not just a technology architecture; it’s an operating model that decentralizes data ownership. You must charter your first cross-functional Data Mesh Squad. This team—composed of a product owner, data engineers, and analysts—is given end-to-end ownership of a single, high-value data domain, like “Customer” or “Inventory.” Their mission is not to fulfill tickets from a central backlog. Their mission is to delight their data customers, which prominently include your AI teams. They are responsible for building, documenting, and supporting their data products. They own the quality, the SLOs, and the roadmap for their domain. This squad is your organizational pilot for treating data as a product. Their success will provide the blueprint for scaling the model across the enterprise.
Checklist Item 2: Define Your Lineage-to-Risk Ratio.
Not all data requires the same level of scrutiny. A full, field-level lineage graph for every dataset is both expensive and unnecessary. The key is to tie your investment in lineage directly to business risk. Introduce the concept of a Lineage-to-Risk Ratio. For a high-risk AI model—like one used for credit scoring or medical diagnosis—mandate 100% field-level lineage for every feature it consumes. The cost of failure is too high to tolerate ambiguity. As experts at Imperva and Ardoq point out, robust data lineage is no longer optional for compliance and risk management in regulated industries. Conversely, for a low-risk internal model that optimizes marketing campaign assignments, a 70% lineage coverage might be acceptable. By creating a formal policy that maps data governance requirements to model risk tiers, you focus your most intensive efforts where they matter most, creating a pragmatic and defensible approach to governance.
Checklist Item 3: Fund Data Fitness as CapEx, Not Overhead.
The most significant barrier to a robust data product strategy is often the financial model. When data platforms and quality initiatives are funded as operational expenses (OpEx), they are viewed as a cost center—a form of overhead that is perpetually squeezed during budget season. This is a strategic error. You must reframe this investment. Building a durable, reliable, well-documented data product is not overhead; it is the creation of a core corporate asset. It is a capital expenditure (CapEx). As explained by financial experts at Splunk and Investopedia, CapEx is an investment in assets that will generate value over many years. Funding your data mesh squads and the platforms they build as a capital investment signals a long-term commitment. It acknowledges that you are building the foundational asset that will power your company’s entire portfolio of future AI initiatives. While the initial cost may be higher, you are building a defensible competitive advantage, not just servicing an IT ticket.
4. The Payoff: From Fragile Models to an AI-Ready Enterprise
Adopting the Twin Engine framework is not a minor adjustment. It is a fundamental shift in how your organization values, manages, and leverages data. The initial investment in new team structures, disciplined contracts, and capital funding yields compounding returns, transforming your enterprise from a place where AI projects struggle to one where they thrive.
The “after” state is starkly different. Time-to-market for new models shrinks dramatically. Data scientists no longer spend 80% of their time discovering and cleaning data; they start with a palette of certified, trustworthy data products, allowing them to focus on modeling and innovation. A project that once took nine months of data wrangling can now be prototyped in weeks.
Operational risk plummets. Models that were once brittle black boxes, prone to silent data drifts, become resilient and auditable. When a model’s performance degrades, the AI-Data Contract’s automated monitoring instantly pinpoints the broken SLO, alerting both the model and data owners before it impacts the business. Audits for regulation and compliance become routine, not fire drills, because lineage is built-in, not bolted-on.
Most importantly, you build a defensible competitive moat. Your competitors, still treating data as a byproduct, will struggle to get their AI initiatives out of the lab. Your organization, powered by the Twin Engine, will be shipping new AI-driven features, optimizing processes, and creating customer value at a pace they cannot match. This advantage doesn’t come from a single magical algorithm; it comes from a superior, AI-ready data asset, built with the discipline of a true product.
5. Conclusion: Your Twin Engine Awaits
 Image generated wityh gpt4o
Image generated wityh gpt4o
The evidence is overwhelming. The path of treating AI and data as separate, siloed strategies leads to the 85% failure rate that Gartner identified. It leads to wasted investment, frustrated teams, and a permanent position trailing your competition. An integrated AI and Data Product strategy isn’t a “nice to have” or an academic ideal; it is the only way to build a scalable, reliable, and high-impact AI capability.
The solution is a conscious, deliberate coupling of your two most critical technology roadmaps. You must map your strategies using the Twin Engine framework, ensuring every AI ambition has a corresponding data product deliverable. You must bind your teams together with the AI-Data Contract, transforming adversarial relationships into accountable partnerships enforced by your platform. And you must fund this work as the critical capital investment it is, creating a durable asset for your company’s future.
This transformation starts with a single question. Start the conversation in your next leadership meeting. Ask the question: “Is our data strategy an engine for our AI, or an anchor holding it back?“. Your twin engine awaits.